The Two-Entity Pattern
AI-generated code has an accretion problem. It’s not bugs. It’s not hallucinations. It’s drift: working code that quietly duplicates or sidesteps what already exists, because anything that wasn’t in the model’s context didn’t get considered.
Picture a todo CRUD app. You ask the model to add a date-validation check on the UI. It writes a validation function right where it’s already working, inside the component file or next to the form handler. It doesn’t go looking for the utils/ folder. It doesn’t check whether a validateDate already exists three files over. It can’t, because that part of the codebase isn’t in its context. So now you have two functions doing the same thing. The feature works. The UI is fine. Your codebase is just slightly worse than it was.
Multiply that across a hundred sessions and what you end up with is a monolith made of well-functioning duplications.
The standard defenses don’t really help here. MVP isn’t inherently anti-architecture, but breadth-first MVP under AI tooling is. With AI you produce features faster than architectural setting can catch up; every new slice is another re-roll on the model’s local guesses about how things fit together. DRY says extract early, but the model can’t actually see what to abstract until it has concrete instances next to each other. Apply both defaults inside an AI-assisted codebase and you accelerate the accretion instead of slowing it.
The obvious modern objection, that agentic coders can grep the repo and find existing helpers, is true but misleading. Models are goal-driven satisficers. They search breadth-first, gather enough to feel sufficient, then proceed. On a real codebase the search saturates context long before any depth-first investigation happens. The model won’t dig into utils/dateUtils/specificFunction to check whether it can be extended; it has already moved on. Context bias kicks in the moment the goal feels close enough to hit.
The Two-Entity Pattern is the inversion of that default.
None of the moves here are new on their own. Build deep, duplicate, extract is basically vertical slice combined with the rule of three. What’s new is the economics. Producing two production-quality entities and then refactoring them together used to be financially insane. Now it’s a Tuesday afternoon. And if standard refactoring really solved accretion, codebases wouldn’t be full of it.
This isn’t a replacement for microservices, DDD, or other architectural choices. It targets entity-driven apps, which happen to cover a large and common case.
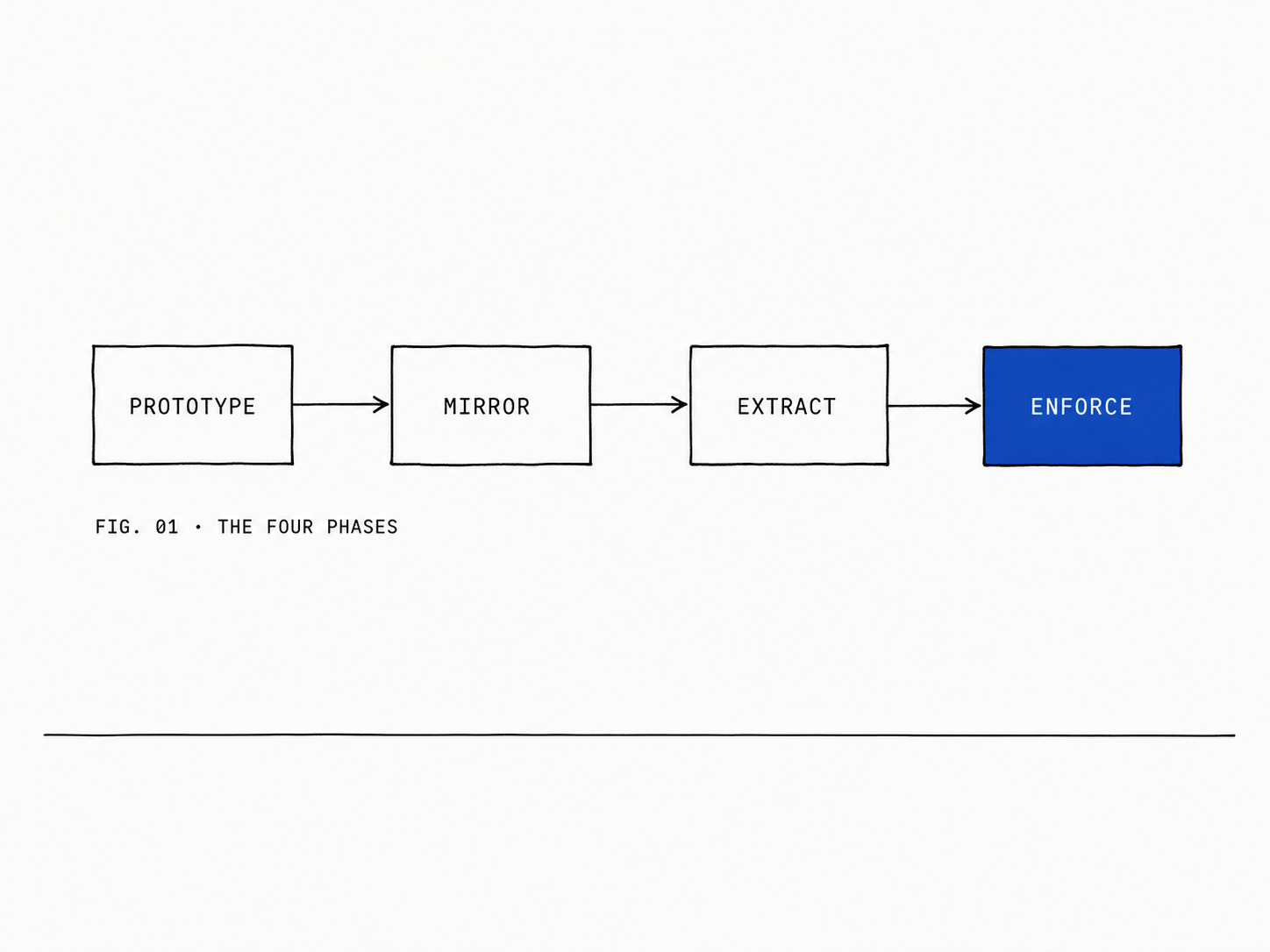
The pattern
The pattern is four phases. Prototype the rails. Mirror the rails. Extract the rails. Enforce the rails.
Prototype the rails. Pick one domain entity. Say Project. Build it end-to-end, fully featured, before anything else exists. Services layer, client-side layer, UI components, edit form, list view with infinite scroll, the lot. You’re not delivering an MVP. You’re delivering a single entity at production quality.
This sounds wrong, and by every conventional product-development heuristic it actually is wrong. You’re spending all your time on one slice while the rest of the app is vapour. Tolerate that. The point isn’t to ship the entity. The point is to produce a playbook.
When is it locked? When the architecture feels honest and the PO accepts the feature set. Both signals required. Architectural taste alone leads to infinite polishing. PO acceptance alone leads to brittle code that gets shipped anyway. You need both, then you stop. You can’t engineer forever.
Mirror the rails. Now build the second entity, Client, using the first as the playbook. Hand the model the project files as context and ask it to replicate the structure for clients. Models are extraordinarily good at lifting patterns. Your client entity will come out looking like your project entity, layer for layer.
But it will duplicate, not abstract. Where ProjectService has a list() method with pagination logic, ClientService will get its own near-identical list() method. The model doesn’t extract on the first pass. It mirrors.
That is the point, and it’s why the pattern needs a third move.
Extract the rails. Run a refactor pass. Point the model at both entities and ask it to identify duplication and extract shared abstractions: a base service, shared list-rendering hooks, common form primitives, whatever scaffolding shape emerges. Then have it update both entities to consume the new abstractions.
A note on what you’re extracting: CRUD scaffolding, not business logic. The wrong-abstraction warning applies to domain behavior, where apparent similarity is often coincidental. CRUD shape is the opposite. List, edit, paginate, validate are essential similarities, done to death across every framework of the last twenty years. The danger zone is the moment you’re tempted to abstract a domain concept because two entities happen to share it. Both have an “approval” field. Both have a “status” lifecycle. Stop. Identical-looking domain methods often model fundamentally different business processes. Scaffolding shape is essential; domain shape is often coincidental.
Concretely, the refactor turns this:
ProjectService.list()
ClientService.list()into this:
createEntityService<Project>('projects', projectSchema)
createEntityService<Client>('clients', clientSchema)The shape stops being something the model assembles fresh each time. It becomes something it composes.
Now you have rails. Every future entity uses them. The model, given the rails as context, will compose against them instead of duplicating. Accretion stops being the default, mostly.
Enforce the rails. Without enforcement, future sessions still drift. Satisficing reasserts itself. The rails need teeth. The enforcement layer has three jobs: detect dead code, detect duplication, and block architectural violations. In a TypeScript stack that might be Knip, jscpd, and custom ESLint rules wired into npm verify. In another stack, use the equivalent: make verify, dotnet test, or whatever your toolchain uses for CI gates. The specific tools matter less than the invariant. Acceptance criteria are not met until the rails are mechanically enforced. That turns rails from convention into constraint, and the model respects constraints far better than conventions.
Why two and not three
Three implementations is the classical extraction trigger, the rule of three. Why stop at two?
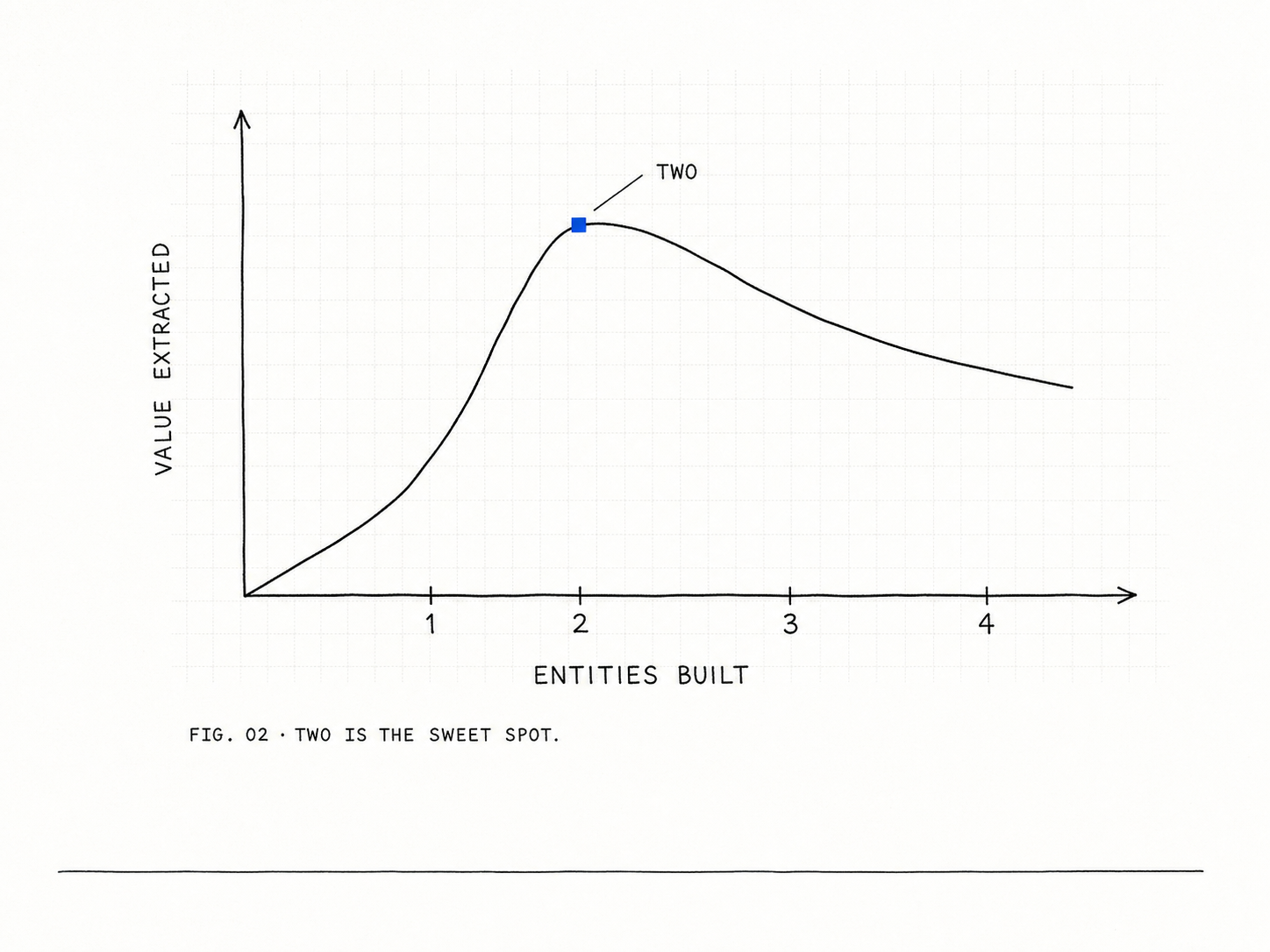
Two concrete instances are enough for the model to recognize the shared shape. Models aren’t dumb; once they’ve seen a master-detail pattern twice, they can extrapolate from it. A Client has many Projects. Lock that, and further similar entities follow by reasoning from the pattern instead of needing another concrete example.
Past that, returns diminish and then go negative. By the third entity, decomposition becomes its own activity. You start extracting things that look similar but aren’t really, generating layers of abstraction whose only justification is “we had three of them.” Abstraction has a cost, paid in indirection. Past two, you’re paying it for nothing.
Two is the sweet spot. It reveals the shape without tempting you into over-extraction.
The keystone risk
This pattern lives or dies on entity one.
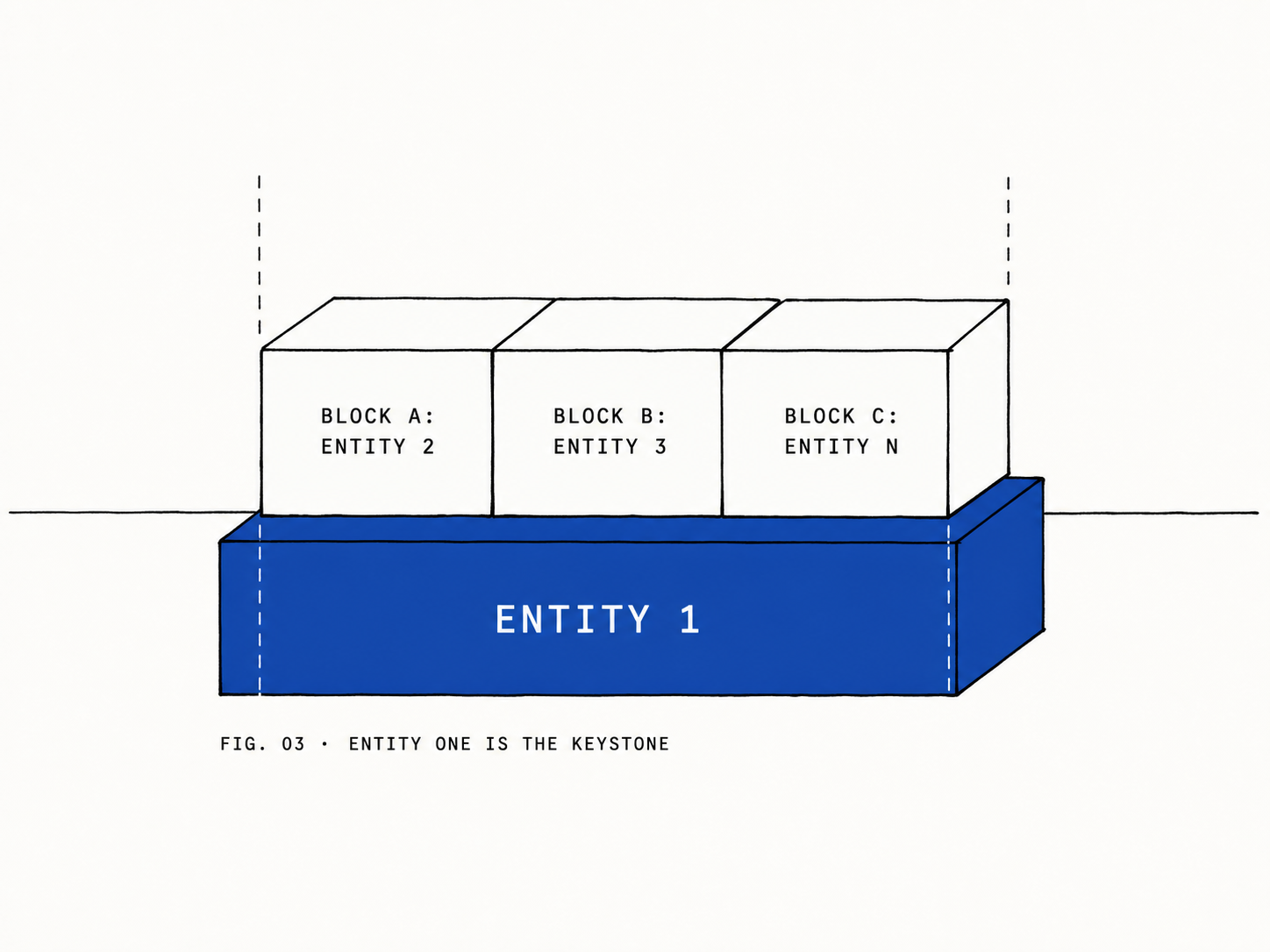
If the first entity has bad architecture, the pattern doesn’t fail. It amplifies the badness. The model’s faithfulness to pattern is exactly what makes it dangerous when the pattern is wrong. Lay the rails in the wrong direction once and every subsequent entity inherits the misdirection with confidence.
There’s no shortcut. Entity one takes engineering judgment to get right. The services layer feels clean. Client/server separation is honest. The obvious next features fit without contortion. You’re not squinting at the shape anywhere. PO acceptance gates the feature set; your own taste gates the structure. Don’t lock until both are satisfied.
If you do lock prematurely, the cost is steep. Better to spend an extra week on entity one than three months retrofitting rails that point sideways.
What you’re really doing
The accretion problem at the top of this post is a context problem.
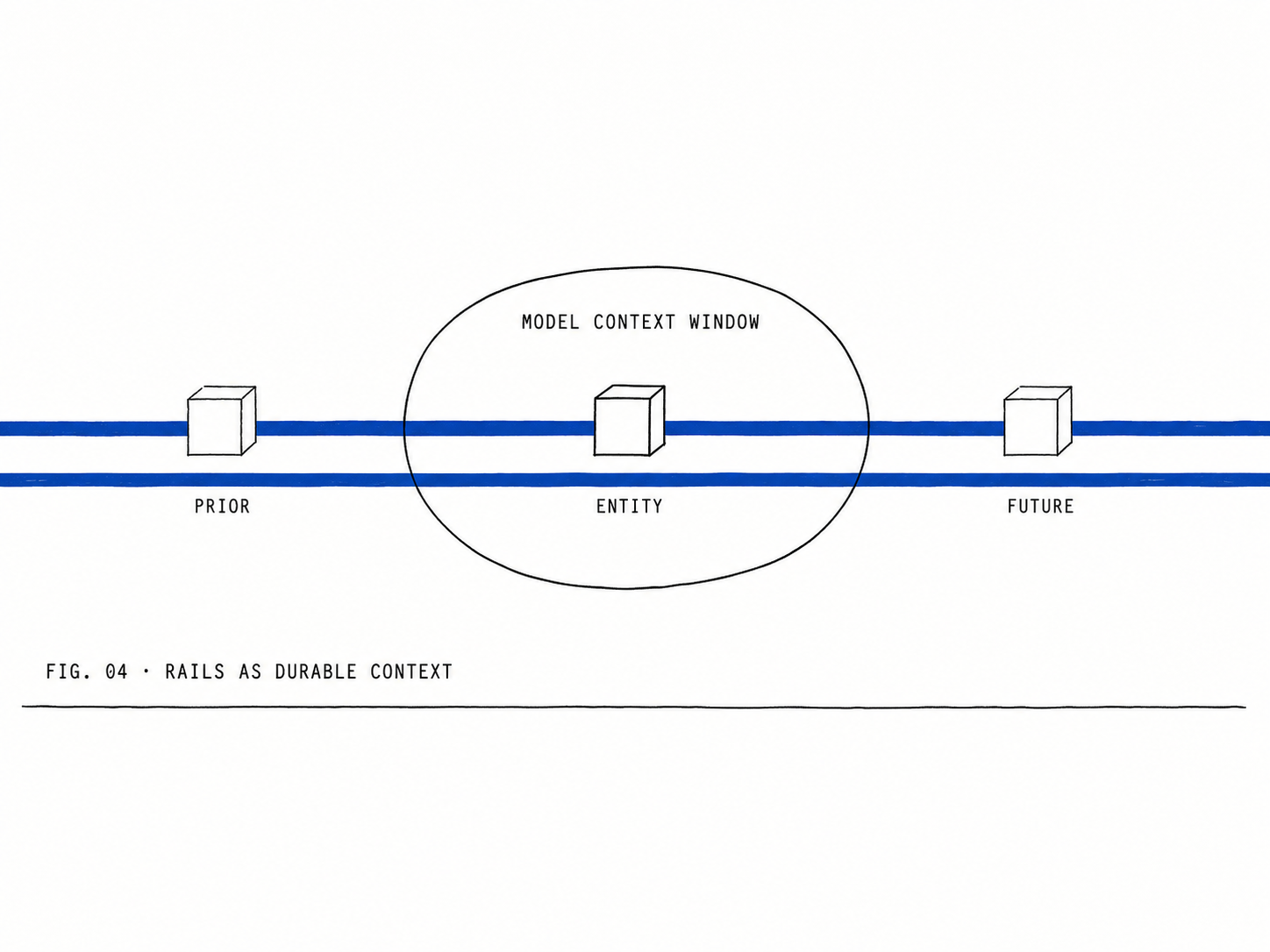 The model doesn’t know what already exists, so it builds in place. Every traditional defense (DRY, MVP, agentic search, careful prompting) fights the symptom.
The model doesn’t know what already exists, so it builds in place. Every traditional defense (DRY, MVP, agentic search, careful prompting) fights the symptom.
The Two-Entity Pattern fights the cause. The helpers you extract in the refactor pass become durable context that travels with the codebase. Every future session that touches the code inherits them as constraints. You’re not just structuring the codebase, you’re structuring the model’s attention.
That’s the whole shift. Stop trying to make the model see the entire codebase at once. It can’t. Lay rails it will naturally hit instead. Architecture in the AI era isn’t only about maintainability for humans. It’s also about cutting the grooves that future sessions will fall into. Two entities is what it takes to lay them right.
This is roughly how we build at Akora when we’re putting AI-assisted delivery against a custom software or Power Platform engagement. If you’re staring at a codebase that’s been growing faster than its rails, we should talk.