Moving DocuShare to SharePoint Online: What Actually Breaks at Scale
DocuShare has been quietly running engineering and manufacturing document libraries since the early 2000s. Drawing registers, work instructions, project files, compliance records. The org buys into Microsoft 365 for everything else, and the day comes when somebody asks why the ten-year-old DMS isn’t in SharePoint Online too. The migration vendor pitches a tool that “just clicks through it.” Then somebody runs the document count and the air leaves the room.
We have done a few of these, and the migration engine we built to run them is in active production use today. At small scale, the click-through tools are fine. At multi-terabyte scale, with engineering metadata, twenty years of accumulated weirdness, and a permission model nobody has audited in a decade, they aren’t. What follows is what actually breaks in a real DocuShare migration, what the architecture has to look like to survive it, why the migration engine is the smaller half of the project, and what you skip when you engage us instead of starting from scratch.
What you are actually moving
A DocuShare library at any real organization carries:
- Hundreds of thousands to millions of documents, often in deeply nested collections that mimic the org chart of a decade ago.
- Custom metadata across a couple of dozen object types: drawing numbers, revision codes, discipline tags, stage gates, asset IDs.
- A permission model with explicit allow and deny rules, group-of-groups, and inherited access that nobody can fully draw on a whiteboard anymore.
- Versioning with full history kept, often for compliance reasons.
- Filenames written by humans over twenty years, in twenty years’ worth of conventions, with twenty years of typos and special characters baked in.
The engagements we’ve shipped have moved several million documents across roughly a million collections, producing multi-terabyte content. The “click a button” tools handle 50 GB cleanly. They do not handle this.
What actually breaks
Path resolution to the source. DocuShare’s web-services API can return wrong children on deep collection hierarchies. Many migration projects start there, lose a week, and switch approaches. The cleaner path: read directly from DocuShare’s hashed physical storage (the platform stores files in bucketed directories computed from the document’s handle ID), or mount DocuShare as a Windows drive via the official drive tool and treat it as a filesystem. The hashed store is faster for bulk; the drive tool is more forgiving for departmental migrations where the hashing math doesn’t line up cleanly. A real migration engine falls back between the two: try hashed first, fall back to the drive when the hash misses.
Title vs filename mismatch. DocuShare’s drive software exposes files by their object title, not their original filename. The database stores both. They are usually different. The downloader has to try the title, the title with original extension appended, the filename, and case-insensitive fallback in the parent folder (in that order) before giving up. Skip this and a noticeable percentage of files will silently fail to resolve.
Names that look fine, aren’t. A folder called Approved Drawings (with a trailing space) is legal in DocuShare and unremarkable on the file system, but breaks SharePoint upload because trailing whitespace gets stripped. A title like Inspection Report Rev.02 looks like a filename with extension .02 and gets misclassified by naive code. Characters like & or # mean different things in a SharePoint URL than they do in DocuShare. You pick a normalization rule for each class of weirdness, apply it during transformation, and log every change so the link-fixup pass at the end has something to work from.
Path length. SharePoint Online enforces a hard 400-character total URL limit, and an effective 250-character per-filename ceiling. DocuShare’s collection hierarchy plus long human-written filenames blows past both on the deeper branches. You need a target IA flatter than the source, with a content-mapping policy that decides what becomes a SharePoint library (top-level container), what becomes a folder, and what happens to the deepest nested items. The rule of thumb we use: root-level files map into a single Documents library; level-1 folders become their own libraries; level-2 and deeper stays as folder hierarchy under those libraries. Deterministic, applied during transformation, produces predictable URLs, and gets the deepest paths back inside the limit.
Metadata mapping is custom for every site. No automated tool maps “Drawing Number” plus “Discipline” plus “Revision” plus “Stage Gate” to SPO content-type columns with the right managed-metadata terms attached. You build a transformation table: DocuShare property on the left, SPO column or term on the right, conversion rules in the middle. You test it against a representative slice, fix the surprises, and run the whole library only after the slice round-trips cleanly. Skip this step and you end up with an SPO library where everything searchable in DocuShare is unsearchable in SharePoint.
Throttling. SharePoint and Microsoft Graph will throttle aggressive migration tools. The minimum viable safety kit: per-site concurrency limits (we use one to ten per site, depending on tenant load), a global cap (around twenty concurrent uploads), exponential backoff with jitter (two seconds to five minutes), explicit handling for HTTP 429 with respect for the Retry-After header, and adaptive throttling that backs off when error rates climb. Run a single-threaded migration and the calendar slips by months. Run an unbounded one and the tenant blocks you an hour in.
There are other things (large-file chunked upload above ten megabytes, permission translation, retention-label assignment, e-signature artifact handling), but the six above are the ones that decide whether the project ships on time.
The architecture that survives at scale
Six pieces, each with one job.
Reader. Discovers and downloads documents from DocuShare. Hashed-store-first with drive-tool fallback. Title-first naming with extension fallback and case-insensitive fuzzy matching. Built to be robust against the source’s twenty years of accumulated weirdness, because that weirdness is going to find every code path you have.
Transformer. This is the project’s intellectual property. Path normalization, name normalization, metadata mapping, permission translation, content-mapping policy that decides library-vs-folder. Every rule is configuration, not code. Every transformation is logged with a before-and-after pair so the audit trail can answer “why did this become that?” months later.
Writer. Pushes documents into SPO. We use the PnP Core SDK on .NET 6, with Parallel.ForEachAsync for concurrency rather than Task.WhenAll (the latter floods the tenant). The PnP context is not thread-safe, so each upload thread clones the context once at start. Chunked upload above ten megabytes is automatic if you let the SDK handle it.
State store. A SQL Server table with one row per document and a state machine: Pending, InProgress, Success, Failed with error class, Throttled, RetryPending, Missing for documents that resolve in the database but not on disk. Each row carries AttemptCount, LastAttemptAt, NextAttemptAt, LastErrorCode, WorkerId, and LockedUntil. Workers atomically claim rows by setting WorkerId under row-level lock; this prevents two workers from racing on the same document. Restart-safe: if a worker dies mid-operation, the row’s lock times out and another worker picks it up.
Reporter. Per-batch progress, per-site throughput, throttling-event counts, and a triage queue of failures organized by error class. The triage queue is the actual deliverable for the migration team: every document that didn’t go through, why, and what the fix is. A multi-terabyte migration produces a long triage queue; the pipeline that surfaces it cleanly is what makes the project finishable.
Orchestrator. The small piece on top: wave selection, batch sizing, retry policy. Most of the orchestrator is configuration.
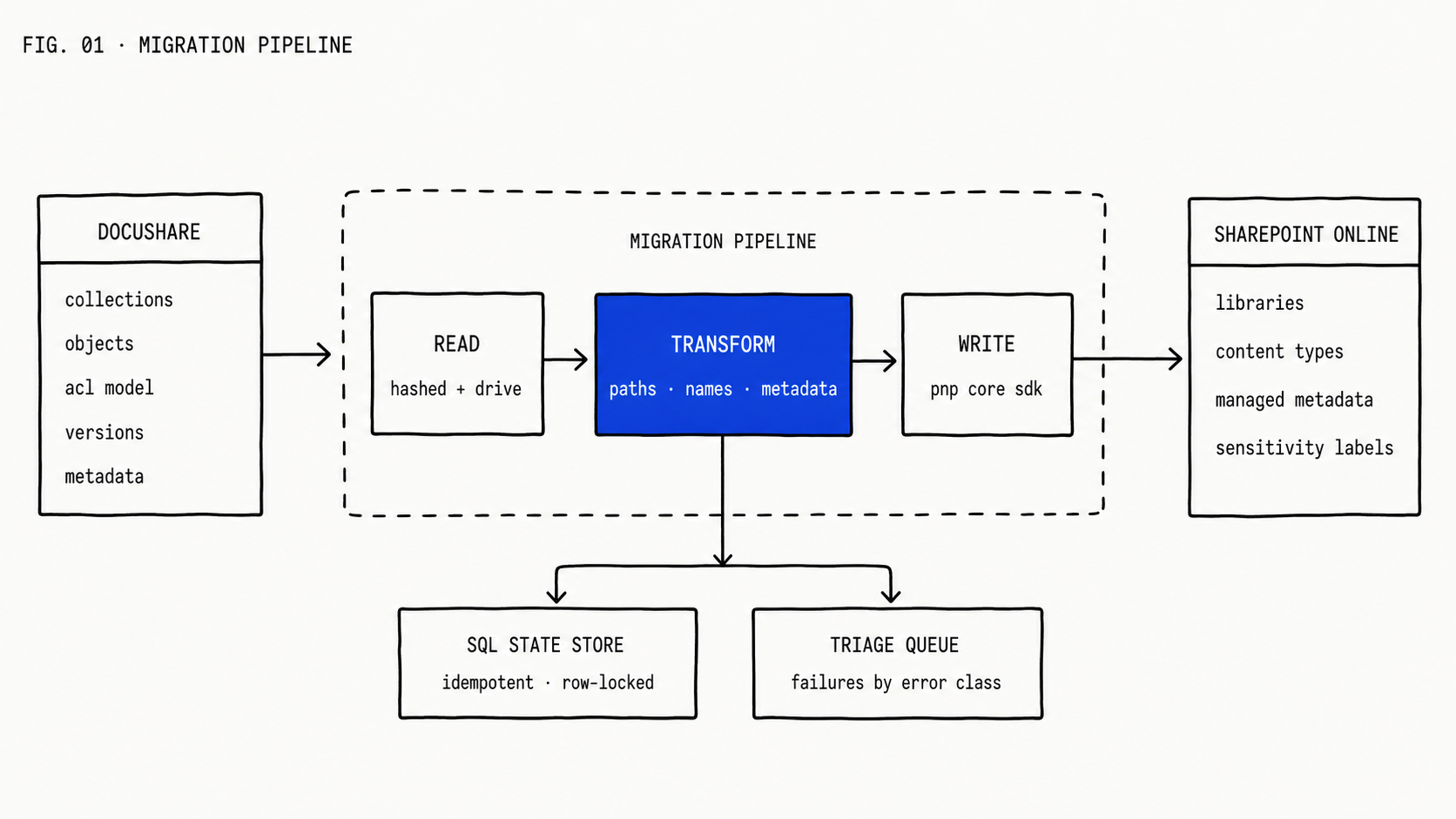
The load-bearing property of the architecture is idempotency. A migration of any real size will fail mid-run at some point. The pipeline must be re-runnable without producing duplicates. We use SHA256 checksums of source content plus deterministic destination naming, so a re-run on a partially-migrated set finishes the unfinished and skips the finished. Get this property right and a multi-terabyte migration takes weeks. Get it wrong and it takes months, most of which are spent reconciling duplicates and chasing ghosts.
Versions are a separate decision
DocuShare keeps full version history of every document. SPO can keep version history too. You will not necessarily migrate the version chain.
In our most recent engagement we migrated current and latest content only and left the historical version chain in place as a read-only archive. The decision was driven by compliance requirements that didn’t extend to mid-document revisions, and by the cost-benefit of doubling the migration time and storage footprint to bring along data that, in practice, nobody opens.
That decision is not a default. It is a conversation with records management before you cut the first byte.
Phased cutover is a people problem
Once the tooling works, the migration plan is a sequence of waves.
Pick the smallest, simplest department as the pilot. Equipment registers, lab work instructions, anything where the metadata model is simple and the user count is low. Cut it over end-to-end. Find what breaks. Fix it. Then the next wave.
The pilot’s purpose is not to test the tooling. By pilot time the tooling works. The pilot’s purpose is to test the people work: the comms about when their library flips, the training on the new metadata they have to apply, the differences in search behaviour, the break-glass plan for the day when somebody can’t find the document they need. Source and target run in parallel during cutover; the cutover playbook tells users when their library flips, what happens to in-flight work, and how to handle a document they were about to save into the old system five minutes before flip time.
None of that is software. All of it is what makes the migration successful from the user’s perspective.
What this is and isn’t
This is custom software development, not licensing. The same shape we apply elsewhere when packaged tools don’t fit, like our oil and gas payroll engine on Dataverse. Off-the-shelf tools (ShareGate, Quest, AvePoint) are excellent for SharePoint-to-SharePoint migrations and basic file-share-to-SPO work. For DocuShare at multi-terabyte scale (especially with engineering metadata and audit-grade requirements), you end up writing the reader, the transformer, and the state store yourself. The value is in the rules, and the rules are not portable.
The migration engine is also the smaller half of the project. The bigger half is the metadata model, the information architecture in SharePoint, the permissions reconciliation, and the change management. The engine is months of engineering on its own. The rest is months of stakeholder work, running in parallel.
We already built the engine
The architecture above is not a sketch. It is in production today, hardened against everything in the “what actually breaks” section because every one of those failure modes is something we have already hit and fixed. PnP Core on .NET 6, the hashed-store-and-drive-tool resolver chain, the SQL state store with worker-locked row claiming, the throttling-aware writer with adaptive concurrency. All of it ships, configured to your DocuShare instance and your SPO tenant.
What that means in practice: when you engage us for a DocuShare to SharePoint Online migration, you skip the four to six months of building, breaking, and re-building a migration engine of your own. We arrive with ours, point it at your source, configure the transformer to your metadata model, and run a pilot wave inside the first month. The engagement starts on the metadata model, the IA redesign in SharePoint, and the cutover plan (the parts that are actually the project), not on writing a migration engine from scratch.
If you’re staring down a DocuShare migration and the vendor’s quote is light on the metadata model, the cutover plan, or both, that is the gap. The day after the click-through tool stops working at scale, you’ll be shopping for somebody who already has the transformer. We do.